Cet article va traiter de la sécurisation informatique suivant trois points : le contrôle des tensions électriques, la sécurisation du stockage sur disque dur via les différents systèmes RAIDs et enfin, la sécurisation du réseau local d’entreprise vis à vis du reste du réseau Internet par l’utilisation d’une zone DMZ et d’un firewall .
Tout d’abord, il faut se protéger des variations intempestives de tension et des coupures de courant .
Pour cela , il existe des onduleurs et des parasurtenseurs .

Les onduleurs fournissent du courant en prenant le relais après une coupure de courant ou une baisse de tension constatée en entrée alors que, les parasurtenseurs, rabaissent la tension lors des surtensions pour éviter d’abimer le matériel . Les onduleurs, aussi appelés UPS (Uninterruptable Power supplies), délivrent du courant à partir de leurs accumulateurs incorporés . Il existe deux types d’onduleurs : on-line et off-line . Avec les onduleurs off-line , les accumulateurs ne sont pas branchés en permanence et prennent le relais uniquement en cas de besoin . La tension de sortie n’est donc pas très régulière pendant le temps de réaction . Avec les onduleurs on-line, les accumulateurs sont branchés en permanence et insérés dans le circuit électrique ce qui permet une régularité de la tension de sortie que le courant provienne du réseau (secteur) ou des accumulateurs .
La capacité des onduleurs n’étant pas infini en cas de coupure, il faut qu’ils puissent envoyer un signal aux ordinateurs quand ils sont presque vide avant la coupure définitive du courant et afin d’arrêter les ordinateurs correctement . Pour cela, ils délivrent en général trois signaux : « tout est ok », « alimentation », « batterie faible » .Des logiciels s’installent sur les postes pour interagir avec les onduleurs : sous Linux Suse, il existe le programme Genpower très facile à configurer . Celui ci doit être éxecuté à chaque démarrage en ajoutant, sous Linux des lignes de lancement dans /sbin/init.d/boot, sous Windows sous forme de service .
Dernier point, le redémarrage automatique des ordinateurs ne doit pas être trop rapide après l’extinction des postes suite à une coupure sinon ils utiliseront le peu d’électricité restant dans les accumulateurs vides pour redémarrer et ils n’auront pas le temps de se ré-éteindre correctement . Il faut donc placer la temporisation dans LILO à un niveau élevé .
De plus, dans les grands réseaux, il faut plusieurs onduleurs pour alimenter tous les postes . Les ordinateurs sont donc répartis entre un onduleur maître et un ou plusieurs onduleurs esclaves . Les divers états de l’UPS sont distribués par le maître aux esclaves à travers le réseau .
En ce qui concerne le stockage, afin de prévenir les pannes et incidents et une éventuelle perte des données stockées sur les disques durs, on utilise des systèmes RAID (Redundant Array on Inexpensive Disks) . Il s’agit d’une méthode de stockage d’informations réparties sur plusieurs disques durs par mirroring des disques, par l’utilisation de somme de contrôle checksum (codes détecteurs ou correcteurs d’erreurs) ou le placement de blocs de données sur plusieurs unités de disques .
Les systèmes RAID peuvent être mis en oeuvre soit, de façon logicielle, soit de façon matérielle .
– Par logiciel : C’est la solution la plus économique car elle est uniquement logicielle et ne met pas en oeuvre de matériel spécifique . C’est uniquement un logiciel présent dans le noyau du système d’exploitation (le kernel Linux par exemple) qui permet de gérer différents RAID sur les disques durs . Cette solution fonctionne aussi bien avec les disques SCSI que IDE ou SATA . Elle présente l’inconvénient d’offrir une vitesse réduite par rapport aux solutions purement matérielles .
– Par le matériel : Cette solution revient plus chère car elle nécessite un contrôleur de disques RAID . Ce sont des cartes enfichables (ISA presque entièrement disparu ou) PCI qui sont installées dans l’ordinateur à la place des contrôleurs classiques IDE ou SCSI . Avec le RAID matériel, le noyau des OS n’a pas besoin d’être adapté .

Six configurations RAID différentes existent : RAID 0, 1, 2, 3, 4, 5
Les principaux et les plus rencontrés sont 0, 1, 4, 5 .
RAID-0 : Deux disques sont couplés . Les données sont réparties par blocs et chaque moitié de bloc est placée sur chaque disque simultanément . De ce fait, la vitesse d’écriture et de lecture est bien plus rapide . Ce procédé est appelé striping . Par contre, en cas de défaillance d’un des disques, toutes les données sont perdues; il n’y a donc pas de tolérances aux pannes .
RAID-1 : Deux disques sont couplés et les données sont écrites en double sur les deux disques . L’un est l’image exacte de l’autre . En cas de défaillance d’un des disques, l’autre étant intact, on récupère toutes les données et la tolérance aux pannes est assurée . Par contre, on perd la moitié de l’espace disponible puisque nos données sont en double . On parle de mirroring .
RAID-4 :
On utilise 3 disques avec des sommes de contrôle ou checksum . Deux disques contiennent les données et le troisième les sommes de contrôle . La somme de contrôle est calculée par exemple par un OU exclusif logique . Quelque soit le disque qui tombe en panne, il est toujours possible de reconstruire le contenu du disque défaillant à l’aide des données des deux autres disques . L’avantage du RAID-4 par rapport au RAID 1 est qu’on peut utiliser les deux tiers de la place au lieu de la moitié . Par contre, l’écriture de donnée sur un disque de donnée, oblige à calculer et écrire la somme de contrôle sur le troisième disque et ralenti donc l’écriture . De plus, le troisième disque est 2 fois plus sollicité que les autres .
RAID-5 :
C’est un perfectionnement de RAID-4 où les données et les sommes de contrôle sont ventilées sur les trois disques de sorte que chaque disque reçoit une charge égale . On utilise toujours les 2/3 de l’espace pour les données (le reste pour le contrôle) . C’est le meilleur des procédés .
Enfin, afin de protéger les réseaux internes des entreprises et autres organisations, des menaces externes provenant de l’Internet et de réseaux non sécurisés, on utilise une architecture Firewall ou Pare-Feu . L’objectif est de se prévenir contre l’accès non autorisé à des données et à des ressources privées . Au passage, le firewall peut permettre de journaliser les échanges, le trafic de données et les tentatives d’accès . Toutes les architectures de Firewall repose sur un Firewall .
Il en existe 3 types de base :
– Filtres de paquets :
Ils analysent les paquets de données au niveau de la couche réseau (couche 3 OSI) et peuvent les filtrer en fonction des adresses de l’expéditeur et du destinataire, du protocole et des numéros de port des applications .
– Relais de circuits :
Les relais de circuits fonctionnent au niveau de la couche transport (couche 4 OSI) . Ils permettent d’utiliser des applications construites sur les protocoles de transport de cette couche (TCP connecté et UDP déconnecté) .
– Passerelles au niveau applications (passerelle de flux applicatifs)
Comme son nom l’indique, ils travaillent au niveau des applications . On définit des proxies (serveurs proxy) spécifiques pour chaque application qui peuvent journaliser et auditer le trafic . Ces proxies peuvent faire du « store and forward » (FTP, SMTP, http …) ou être interactif (Telnet) suivant le type de trafic . De plus, ils peuvent gérer des mécanismes d’authentification (par exemple pour Rlogin ou Telnet) . Le temps de latence est plus élevé que le « Filtering Gateway » (=Filtres de paquets) .
Le paramétrage du firewall doit obéir à une logique stricte : On interdit tout par défaut . On définit les autorisations uniquement pour ce dont on a besoin . « Tout ce qui n’est pas autorisé est interdit » . Il faut valider l’utilisation de chaque service réseau . C’est la démarche de paramétrage la plus sûre .
Exemple de commande Linux de paramétrage du firewall pour le serveur de courrier :
ipfwadm –F –a accept –b –P tcp –D mail.mafirme.fr 25
Les architectures de Firewall sont nombreuses suivant les moyens financiers qu’on est prêt à leur consacrer et le degré de sécurité recherché .
Voici les schémas de deux variantes : la plus simple (moins coûteuse) et la plus compliquée (plus sûr mais chère)
Cas 1 : Firewall avec routeurs de filtrage

Le routeur de filtrage contient les autorisations d’accès basées exclusivement sur les adresses IP et les numéros de port .
Cas 2 : Firewall avec sous réseaux de filtrage (zone DMZ démilitarisée)
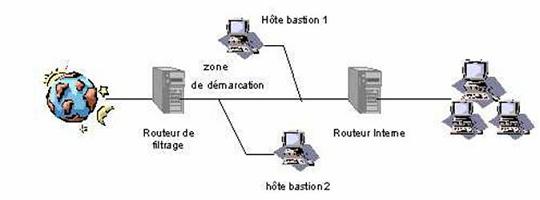
Un Firewall avec sous-réseau de filtrage se compose de deux routeurs : L’un est connecté à Internet, et l’autre à l’Intranet/LAN. Plusieurs réseaux bastions peuvent s’intercaler pour former entre ces deux routeurs, en quelque sorte, leur propre réseau constituant une zone tampon entre un Intranet et l’Internet appelée «zone démilitarisée» . Les serveurs accessibles par Internet (HTTP, FTP, E-mail, DNS, Gopher) doivent être placés dans cette zone démilitarisée . De l’extérieur, seul l’accès aux réseaux bastions est autorisé. Le trafic IP n’est pas directement transmis au réseau interne. De même, seuls les réseaux bastions, sur lesquels des serveurs Proxy doivent être en service pour permettre l’accès à différents services Internet, sont accessibles à partir du réseau interne.
Le Routeur interne :
– Autorise le trafic entre le bastion 1 et les machines internes et inversement.
– Interdit tout autre trafic.
Le Routeur externe :
– Filtre le trafic entre le monde extérieur et le bastion 2.
– Interdit tout autre trafic direct (donc pas de trafic direct entre le réseau interne et l’extérieur).
Le bastion interne :
– Assure les fonctions de DNS vis à vis du réseau interne en envoyant ses requêtes au bastion externe.
– Assure les fonctions de proxy avec authentification pour les applications distantes (Telnet, Rlogin, FTP)
– Assure le relais du Mail sortant(SMTP).
Le bastion externe :
– Filtre au niveau applicatif les paquets en direction du réseau interne
– Assure le relais X11 de l’extérieur vers l’intérieur, sur autorisation.
– Assure le relais du Mail entrant(POP).
– Assure les fonctions de DNS vis à vis du réseau externe.
Le bastion interne héberge des services .
On peut installer sur l’ordinateur bastion un serveur de noms comme NAMED sous Linux par exemple . Ce serveur DNS est recensé comme serveur de noms sur le réseau . Les ordinateurs internes envoient leurs requêtes de noms à l’ordinateur bastion qui, grâce à sa connexion à Internet, traite la requête DNS et retransmet la réponse au client .
Sur l’ordinateur bastion, on trouve aussi un serveur proxy (=masquage IP = masquerading host=1 seule IP Internet pour de nombreuses IP LAN)comme SQUID sous Linux . Les clients du réseau ne s’adressent pas directement à Internet mais passent par le proxy après que les logiciels clients utilisés soient paramétré pour le passage par proxy (ex : navigateur http, FTP, Gopher …) . Le proxy a un cache qui peut faire gagner du temps si il possède déjà les données requises dans le cache .
L’ordinateur bastion peut enfin jouer le rôle de serveur de messagerie central . Il est alors spécifié comme serveur SMTP sut tous les ordinateurs du réseau et joue aussi le rôle de serveur POP3 . Précisément, il réceptionne le courrier des clients et le réexpédie sur Internet (fonction SMTP). Quand aux messages en provenance de l’Internet, ils sont réceptionnés sur l’ordinateur bastion qui les redistribue localement aux différents destinataires (fonction POP3 ou IMAP4) . Tout cela nécessite l’installation de SENDMAIL sous Linux et d’un démon POP3 . De plus ; l’ordinateur bastion doit être recensé comme échangeur de courrier (enregistrement MX sous Linux) dans la base de données DNS du domaine de la société .
Exemple d’entrée DNS : IN MX 10 mailserver.mafirme.fr
A noter que l’ordinateur bastion et le serveur de messagerie peuvent être deux machines différentes mais dans tous les cas, le serveur de messagerie doit aussi être dans la zone DMZ (=démilitarisée) .
Le pare feu peut limiter les débits et constituer un goulet d’étranglement des performances réseaux .
«Je prends une trame, je l’examine, je la transmets ou la bloque en fonction de règles… », tout cela prend du temps.
Les tâches que le Firewall a à accomplir sont très exigeantes en termes de charge CPU. L’installation d’un FireWall sur un serveur plus puissant ne résout pas tous les problèmes de capacité . De plus, tout le trafic passe par le firewall qui est alors un élement vital . Si il tombe, tout le trafic est bloqué .
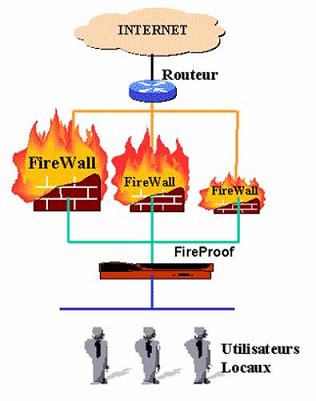
Aussi, il existe une architecture dite FireProof : Il s’agit de multiplexer le travail de filtrage sur plusieurs firewalls ce qui permet de répartir les charges et de lutter contre les pannes : Si un Firewall tombe en panne, puisqu’il n’est pas le seul, le travail est répartit automatiquement sur les autres et le réseau n’est pas bloqué .